15 Jun, 2026 05:10
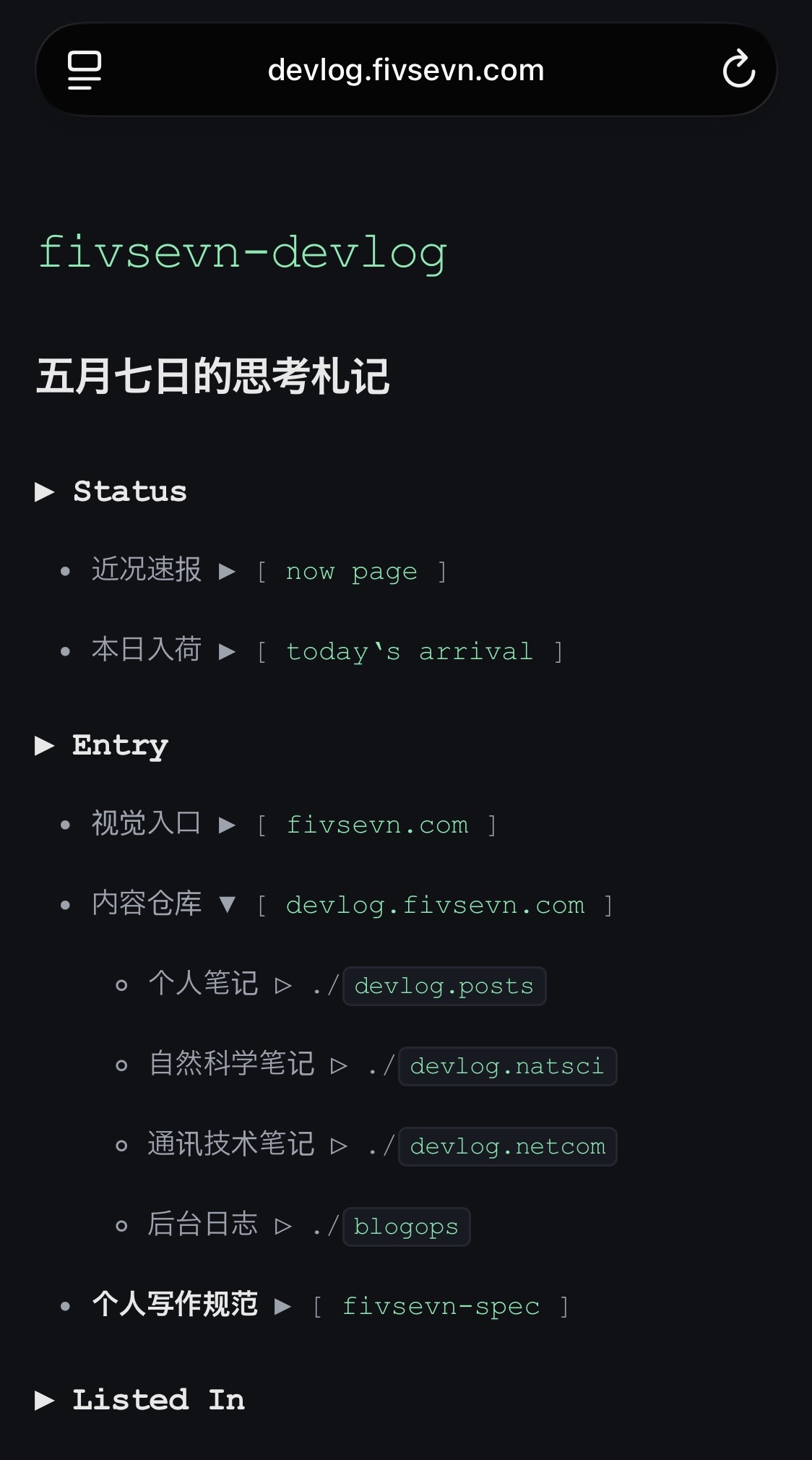
更加简洁的 devlog 主页!
更加简洁的 devlog 主页!
以后发布文字内容可以直接更改下面这个 trigger 文档并 commit。
我把大部分发布流程转移到 GitHub 里,直接编辑、提交、发布完成。这样既能保留完整归档,也能兼顾内容发布。

暴龙beer
根据这篇报道,D-Day 82 周年时,历史学家 Alex Kershaw 在 X (前推特)上“实时直播”诺曼底登陆,把 1944 年当天发生的事件按原时间点重新发布出来,比如哪一架运输机起飞、伞兵什么时候空降、登陆部队什么时候上岸,让读者像在现场接收战况一样感受 D-Day。
Alex Kershaw 账号:https://x.com/kershaw\_alex
可以作为策展参考。在保证资料数量和质量的基础上,如何对素材进行重新排列组合、吸引注意力。
注:
D-Day 通常指 1944 年 6 月 6 日的诺曼底登陆日,也就是二战中盟军从英国横渡英吉利海峡,在法国诺曼底海岸登陆,正式开始从西线反攻纳粹德国的那一天。
更准确地说,D-Day 原本是军事术语。D 是 “Day” 的占位符;D-Day 的意思是“行动开始日”;类似地,H-Hour 指“行动开始时刻”。
军方在计划作战时,常常还不知道确切日期,所以会用 D-Day 来表示“那一天”。比如:
但后来因为诺曼底登陆影响极大,D-Day 几乎就专门指 1944 年 6 月 6 日。
博客的图片和视频内容存放在哪里、如何在页面或者正文内容当中引用,我的方法归纳在这里:https://devlog.fivsevn.com/blogops/content/blogops-assets-media-reference-001.html
以前看到这个:
Created by Nickilism 在 Safari 中分享 URL 给这个 Shortcuts,会自动生成 Markdown 文件,再选择发给如 ChatGPT、Grok 等 Chatbot 来实现文章的总结。
作者站点:
这个快捷指令特别好。我主要用它来抓取原文,再交给 AI 做逐句翻译和整理。
今天我改了一下内容抓取方式:原版用的是 iOS / Safari 自带的网页正文提取,也就是先把网页识别成 Article,再转成 Markdown;我改成了用 Jina Reader 提取正文,也就是把网页 URL 拼成 https://r.jina.ai/原链接,由 Jina Reader 返回 Markdown。
这样改的原因是:文章比较长、网页结构比较复杂的时候,Safari 不一定能抓全正文;Jina Reader 通常更适合把网页转换成完整的 Markdown 文本。当然,它依赖外部服务,高频或批量使用时可能会遇到限制,必要时需要 API key 或付费方案。但我目前只是针对部分文章手动整理,用量不高,问题不大。
我保留快捷指令这一层,是因为我想把交给 AI 的指令提前打包好。我的前置指令里包含 frontmatter 写法、翻译要求、格式规范等内容。这样从 Safari 分享网页后,快捷指令就能自动完成“抓取网页 → 组装提示词 → 输出 Markdown 文件”的流程,再把结果交给 ChatGPT、Grok 或其他工具处理。
现在图片上传到 GitHub 对应的仓库文件夹,就可以自动更新到博客对应栏目🥳。上传到 YouTube 频道存档的视频也会自动同步更新到对应的博客页面。详见:https://github.com/fivsevn/fivsevn-assets/blob/main/README.md 有空需要把博客维护日志(https://devlog.fivsevn.com/blogops/)更新一下。有 ChatGPT 作为助手,不少问题都能当下解决、而且更新迭代变得很快。不过,是时候为当下的状态留个档了。
https://www.themarginalian.org/2026/06/01/nathaniel-hawthorne-classification/
译文由 ChatGPT 翻译,仅供我个人阅读和学习使用,不用于公开传播或商业用途;原文版权仍归作者及相关权利方所有。
标题:人与人之间真正的三种区别 作者:MARIA POPOVA
也许,意识的演化,本就是为了从万物那不可穷尽、不可理喻的整体中,筛选出与我们有关的部分;为了把世界拆解成概念,并在混沌之中找到某种秩序。我们继承下来的认知本能,是一种永不安宁的渴望:想要弄清事物如何彼此关联,又各自归属于何处。于是,我们把这种渴望塑造成法律和标签、尺度和衡量、等级和类别。
这种分类的本能曾使我们受益。它让我们得以创造音乐,发现行星运行的规律,建立民主制度。可是,它也潜伏在我们发明过的每一种“主义”之下,潜伏在每一个刻板印象和每一次种族屠杀之下,潜伏在每一种把人化约为变量、再把变量相加以计算“我们是谁”的算法之下。它也潜伏在我们日常交换的种种成见之中,使我们把偏见当作筹码,误以为那就是真正与他人相遇的方式。
两个世纪前,纳撒尼尔·霍桑) (1804年7月4日—1864年5月19日) 曾为这种双刃的本能,提出过一剂简洁而有力的解药。
1836年秋天,霍桑在一则笔记中写下如下思考。当时,他刚搬到……不久,也刚写下关于“如何不虚度此生”的沉思。他提出,我们应当修订惯常用来划分人类的分类体系:让分类重新把人还给人,让我们看见,真正联结我们的,远比我们用以彼此区隔的身份、阵营和归属更为强大。他写道:
应当建立一种新的社会分类法。人们不再按照贫富、贵贱来区分,而应当这样归类:
第一,按照各自的悲伤来分。譬如,凡是正在为亲友离世而哀悼的人,无论住在华宅还是茅舍,无论身上的黑衣是粗布还是细料,都应归为同一类。
第二,凡患有同样疾病的人,无论他们躺在锦缎床帐之下,还是躺在草褥上,或是在医院病房里,都应归为同一类。
第三,凡犯有同样罪过的人,无论世人是否知晓;无论他们是在牢狱中消磨时日、等待绞刑架,还是受人敬重地行走在人群之中,也都应归为同一类。
然后,再把整个世界一并概括、归为一类。因为没有人能声称自己完全免于悲伤、罪与疾病;即便真有人能够免于这些,死亡也会像一位伟大的父亲,把所有人扫进同一道幽暗之门——所有人,都是他的孩子。
这是何等宏阔的一种提醒:在精神触及骨骼的深处,我们面对的是同一种挣扎——渴望安全,渴望被看见,渴望从短暂而迷惘的生命中,夺回一点意义,夺回一点惊奇。

https://www.theguardian.com/australia-news/2026/jun/05/live-cockroaches-seized-nsw-breeder-australia
ChatGPT:
这篇《卫报》报道的核心是:澳大利亚新州 Bathurst 一家商业繁殖者被查获 10万多只活体外来蟑螂,估值最高约 20万澳元,被称为澳大利亚迄今最大规模的非法外来无脊椎动物查获案。
主要信息:
这则新闻的重点不只是“蟑螂数量惊人”,而是澳大利亚对外来物种、生物安全、非法宠物贸易的高压监管。澳大利亚生态系统相对隔离,外来物种一旦逃逸或建立野外种群,治理成本很高,所以执法逻辑偏预防性。
https://www.nature.com/articles/d41586-026-01728-w AI 略读:
这篇 Nature 文章的核心意思是:关于“人类最长能活多久”的很多说法其实证据很不稳,当前科学并不能可靠地给出一个明确上限。
它不是一篇原创研究论文,而是 Nature 的 Book Review / 访谈式文章,围绕 Saul Justin Newman 的新书 Morbid: Debunking Modern Longevity Science 展开;Nature 页面标题是 “How long can humans live? We simply don’t know”,副标题直接说:关于人类寿命上限的许多主张充满炒作、数据缺陷和粗糙科学。
主要讲了几层:
- 不要轻信“人类寿命有精确上限”或“可以无限延长”的断言。 文章把焦点放在极端长寿研究的数据质量上。Nature 页面列出的背景文献包括 2016 年 Nature 论文“人类寿命有自然上限”的主张,以及 2018 年 Science 论文关于极高龄死亡率平台期的相反方向主张,说明这个问题本身长期有争议。
- Newman 的批评是:很多“超级百岁老人”数据可能被登记错误、年龄误报、文书错误、养老金欺诈等污染。 UCL 对 Newman 相关工作的介绍称,他的研究认为极端高龄记录呈现出文书错误和养老金欺诈的模式;例如一些地区所谓极端长寿率,反而和贫困、缺少出生证明、更差登记系统等因素相关。
- “蓝区”也被放在怀疑对象里。 文章配图提到日本冲绳常被称为“蓝区”,即大量人活到高龄的地区;Newman 的相关批评则认为,许多蓝区的长寿叙事建立在不可靠人口记录和未经充分验证的生活方式解释上。
- 文章的结论不是“人类不能活很久”,而是“我们现在不知道”。 它质疑的是:用极少数、极易出错的超高龄个案来推导人类寿命极限,统计基础很脆弱。Newman 的书页介绍也把这本书定位为对现代长寿科学中误导性主张、错误假设和可疑数据的批判。
一句话概括:这篇文章是在泼冷水:长寿科学里很多关于“寿命极限”“蓝区秘诀”“活到 120/150 岁”的说法,可能建立在烂数据和过度营销上;真正严谨的答案是,人类寿命上限目前还不能可靠确定。
另外,与寿命研究本身无直接关系的话题,从经验和直觉来讲,冲绳并不是一个特别容易开展外部调查的地区。此处暂且不做展开。
类似 Upstract(https://upstract.com)和 Buzzing(https://www.buzzing.cc)这类资讯聚合网站,很适合快速浏览各类信息。另外,像 garss(https://github.com/zhaoolee/garss)这种可以直接生成每日新闻列表的项目,也非常方便。
我也让 ChatGPT 帮我做了一个完全个人化的每日新闻更新页面:https://devlog.fivsevn.com/intake/。目前刚保证能够运行,页面质量和资讯源会在随后慢慢提升和更新。
Without stakes, it’s hard to spot a lie. There’s no fear of being caught. Lie to me S2E11